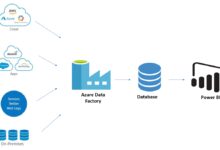
Ever wondered how companies move and transform massive data without breaking a sweat? Meet Azure Data Factory — your cloud-based data integration powerhouse, simplifying ETL, orchestration, and automation with ease and scalability.




What Is Azure Data Factory and Why It Matters
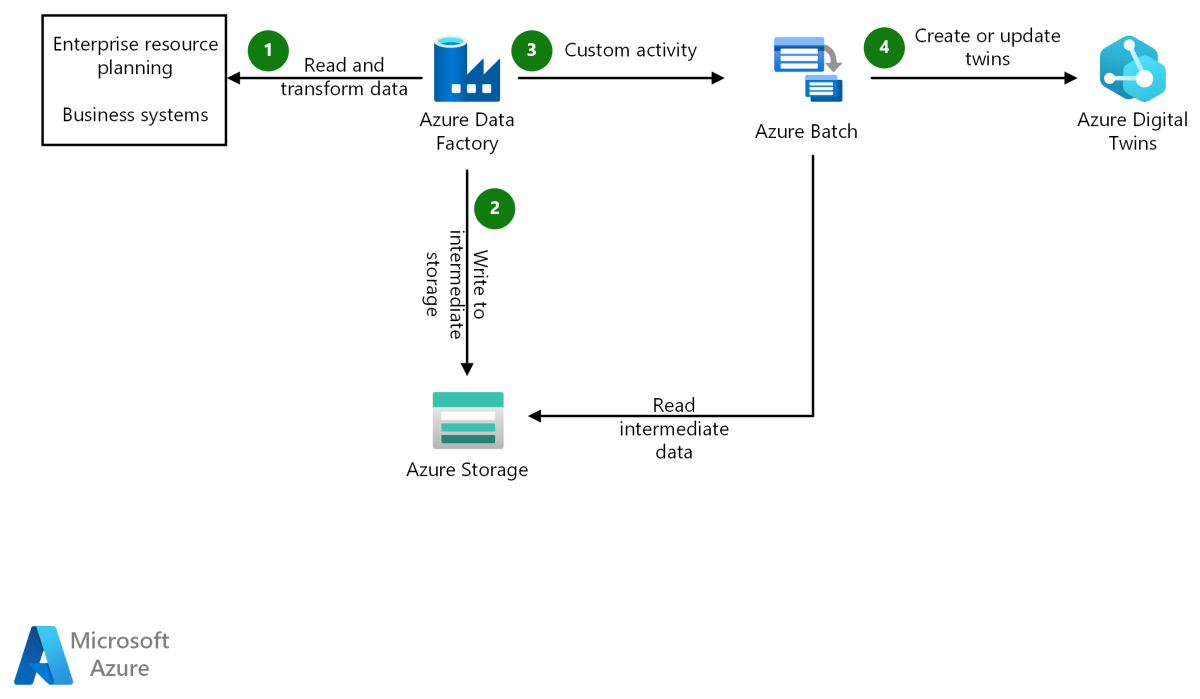
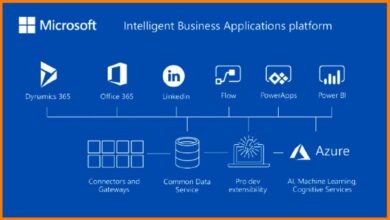
Azure Data Factory (ADF) is Microsoft’s cloud-native data integration service that enables organizations to create data-driven workflows for orchestrating and automating data movement and transformation. Built on a serverless architecture, it allows you to ingest, process, and deliver data from diverse sources—on-premises, cloud, or hybrid environments—without managing infrastructure.
Core Purpose of Azure Data Factory
The primary goal of azure data factory is to streamline the Extract, Transform, Load (ETL) and Extract, Load, Transform (ELT) processes. It acts as a central hub where data pipelines are designed, scheduled, monitored, and managed. Whether you’re migrating data to a data warehouse like Azure Synapse Analytics or preparing datasets for machine learning in Azure Machine Learning, ADF plays a pivotal role.
- Automates data workflows across cloud and on-premises systems
- Supports both batch and real-time data processing
- Enables seamless integration with Azure and third-party services
How ADF Fits Into Modern Data Architecture
In today’s data-driven world, businesses rely on timely insights. Azure data factory bridges the gap between raw data sources and analytical platforms. It integrates with services like Azure Blob Storage, Azure SQL Database, and even non-Microsoft platforms such as Amazon S3 and Salesforce.
“Azure Data Factory is not just a tool—it’s the backbone of modern cloud data integration.” — Microsoft Azure Documentation
Key Components of Azure Data Factory
To fully harness the power of azure data factory, it’s essential to understand its core building blocks. Each component plays a specific role in designing and executing data pipelines.
Data Pipelines and Activities
A pipeline in Azure Data Factory is a logical grouping of activities that perform a specific task. For example, a pipeline might extract sales data from an on-premises SQL Server, transform it using Azure Databricks, and load it into Azure Data Lake Storage.
- Copy Activity: Moves data from source to destination
- Transformation Activities: Includes HDInsight, Databricks, and Azure Functions
- Control Activities: Orchestrate pipeline execution (e.g., If Condition, ForEach)
Linked Services and Datasets
Linked services define the connection information to external resources. Think of them as connection strings. Datasets, on the other hand, represent the structure of the data within those linked services.
- Linked services connect to databases, storage accounts, APIs
- Datasets define data objects like tables, files, or collections
- Both are referenced within pipeline activities
Integration Runtime
The Integration Runtime (IR) is the compute infrastructure that ADF uses to run activities. It comes in three flavors:
- Azure IR: For cloud-to-cloud data movement
- Self-Hosted IR: Enables secure data transfer from on-premises networks
- SSIS IR: Runs legacy SQL Server Integration Services packages in the cloud
How Azure Data Factory Enables ETL and ELT Workflows
One of the most powerful uses of azure data factory is in building ETL (Extract, Transform, Load) and ELT (Extract, Load, Transform) pipelines. These workflows are the foundation of data warehousing and analytics.
ETL vs. ELT: What’s the Difference?
ETL involves transforming data before loading it into a destination, typically used when the destination system has limited compute power. ELT, on the other hand, loads raw data first and then transforms it, leveraging the destination’s processing capabilities—ideal for cloud data warehouses like Snowflake or Azure Synapse.
- ETL: Transformation happens before load (pre-processing)
- ELT: Transformation happens after load (post-processing)
- Azure Data Factory supports both patterns seamlessly
Building an ETL Pipeline in ADF
To create an ETL pipeline, you start by connecting to a source (e.g., SQL Server), use a transformation activity (like mapping data flows or Azure Databricks), and then load the result into a data warehouse.
- Use Copy Activity to extract data
- Apply transformations using Mapping Data Flows or external compute
- Load into Azure Synapse or Azure SQL Database
Real-World Example: Retail Sales Analytics
Imagine a retail chain collecting sales data from 500 stores. Azure data factory can automate the daily aggregation of this data, clean it (removing duplicates, standardizing formats), and load it into a central data warehouse for reporting in Power BI.
Learn more about ETL best practices at Microsoft Learn: Copy Data Tool.
Mapping Data Flows: No-Code Data Transformation
One of the standout features of azure data factory is Mapping Data Flows—a visual, code-free interface for designing data transformations. It runs on Apache Spark, providing scalable, serverless processing.
What Are Mapping Data Flows?
Mapping Data Flows allow you to build transformation logic using a drag-and-drop interface. You can perform operations like filtering, joining, aggregating, and deriving new columns without writing a single line of code.
- Fully integrated into ADF pipelines
- Auto-scales based on data volume
- Supports schema drift and complex data types (JSON, arrays)
Key Transformation Capabilities
With Mapping Data Flows, you can implement advanced transformations such as:
- Derived Column: Create new fields using expressions
- Aggregate: Summarize data (e.g., total sales per region)
- Join: Combine data from multiple sources
- Surrogate Key: Add auto-incrementing IDs
- Pivot/Unpivot: Reshape data for analysis
When to Use Data Flows vs. Custom Code
While data flows are powerful, they’re not always the best choice. For highly complex logic or machine learning preprocessing, you might prefer using Azure Databricks or Azure Functions within your pipeline. However, for 80% of transformation tasks, Mapping Data Flows offer a faster, more maintainable solution.
Orchestration and Scheduling in Azure Data Factory
One of the most powerful aspects of azure data factory is its ability to orchestrate complex workflows across multiple systems and services.
Trigger Types and Scheduling Options
ADF supports several trigger types to automate pipeline execution:
- Schedule Triggers: Run pipelines on a time-based schedule (e.g., every hour)
- Tumbling Window Triggers: Ideal for time-series data processing with dependencies
- Event-Based Triggers: Start pipelines when a file is added to Blob Storage or an event is published
Dependency Management and Pipeline Chaining
You can chain pipelines together using control activities. For example, a “Data Validation” pipeline can run only after a “Data Ingestion” pipeline succeeds. This ensures data quality and process integrity.
- Use Execute Pipeline activity to call other pipelines
- Implement error handling with Try-Catch logic via If Conditions
- Set up dependencies using tumbling window triggers
Monitoring and Alerting
Azure Data Factory provides a robust monitoring experience through the Azure portal. You can view pipeline runs, inspect activity logs, and set up alerts using Azure Monitor.
- Track execution duration, success/failure rates
- Set up email or SMS alerts for failed pipelines
- Use Log Analytics for advanced querying and dashboards
Security, Compliance, and Governance in ADF
When dealing with enterprise data, security is non-negotiable. Azure data factory offers multiple layers of protection to ensure data integrity and compliance.
Authentication and Access Control
ADF integrates with Azure Active Directory (AAD) for identity management. You can assign granular roles using Azure RBAC (Role-Based Access Control).
- Contributor: Can create and edit pipelines
- Reader: Can view but not modify resources
- Data Factory Contributor: Specific role for ADF management
Data Encryption and Network Security
All data in transit and at rest is encrypted. You can also enable private endpoints to ensure data doesn’t traverse the public internet.
- Use Private Link to connect ADF to private networks
- Enable Managed Identity for secure authentication
- Integrate with Azure Key Vault for credential management
Compliance and Auditing
Azure Data Factory complies with major standards like GDPR, HIPAA, and ISO 27001. Audit logs are available via Azure Monitor and can be exported for compliance reporting.
Explore compliance details at Azure Compliance Documentation.
Integration with Other Azure Services
The true power of azure data factory emerges when it’s used in conjunction with other Azure services. This ecosystem approach enables end-to-end data solutions.
ADF and Azure Databricks
For advanced analytics and machine learning, ADF can trigger Databricks notebooks or JAR files. This allows data engineers to leverage Spark for heavy-duty transformations.
- Pass parameters from ADF to Databricks
- Monitor notebook execution status in ADF
- Scale compute dynamically based on workload
ADF and Azure Synapse Analytics
Azure Synapse is a unified analytics platform that combines data integration, warehousing, and big data analytics. ADF is deeply integrated with Synapse, allowing seamless data movement and pipeline sharing.
- Use Synapse pipelines (based on ADF) within the same workspace
- Share datasets and linked services across services
- Run serverless SQL queries on raw data in data lakes
ADF and Power BI
While ADF doesn’t directly generate reports, it prepares the data that Power BI consumes. By automating data refresh pipelines, ADF ensures Power BI dashboards are always up to date.
- Schedule data refreshes in Power BI via ADF triggers
- Use ADF to clean and model data before loading into Power BI datasets
- Monitor data pipeline health to prevent dashboard outages
Best Practices for Using Azure Data Factory
To get the most out of azure data factory, follow these proven best practices.
Design for Reusability and Modularity
Break down complex pipelines into smaller, reusable components. Use parameters and variables to make pipelines dynamic and adaptable to different environments.
- Create template pipelines for common tasks
- Use global parameters for environment-specific values
- Leverage pipeline templates from the Azure Data Factory marketplace
Optimize Performance and Cost
Since ADF uses pay-per-use pricing for data flows and integration runtimes, optimizing performance can reduce costs.
- Use auto-resolve integration runtime for lightweight tasks
- Size your data flow compute clusters appropriately
- Minimize data movement by filtering early in the pipeline
Implement Robust Error Handling
Always plan for failures. Use retry policies, logging, and alerting to ensure pipeline resilience.
- Set retry counts and intervals for activities
- Log errors to Azure Monitor or Log Analytics
- Use webhooks to notify teams of critical failures
Common Use Cases and Real-World Applications
Organizations across industries use azure data factory to solve real business problems.
Data Migration to the Cloud
Many companies are moving from on-premises databases to cloud data platforms. ADF simplifies this with its self-hosted integration runtime and robust copy capabilities.
- Migrate SQL Server databases to Azure SQL
- Replicate Oracle data to Azure Data Lake
- Perform one-time or continuous data sync
IoT and Real-Time Data Processing
With event-based triggers, ADF can respond to data from IoT devices in near real-time. For example, processing sensor data from manufacturing equipment and loading it into a time-series database.
- Trigger pipelines when new files arrive in IoT Hub
- Enrich data with contextual information
- Feed insights into dashboards or alerting systems
Automated Reporting and BI Refresh
Finance and operations teams rely on daily reports. ADF can automate the entire data preparation process, ensuring reports are generated on time, every time.
- Extract data from ERP systems like SAP
- Transform and consolidate into a data mart
- Trigger Power BI dataset refreshes automatically
Getting Started with Azure Data Factory
Ready to dive in? Here’s how to start using azure data factory.
Creating Your First Data Factory
Log in to the Azure portal, create a new resource, and search for “Data Factory.” Choose the version (v2 is current), select your subscription and resource group, and deploy.
- Use the Azure portal or ARM templates for deployment
- Enable Git integration for version control
- Choose between Data Factory and Data Factory (Version 2)
Using the UI vs. Code-Based Development
ADF offers a visual interface (Data Factory UX) for designing pipelines. Alternatively, you can use JSON, ARM templates, or tools like Visual Studio Code with the Azure Data Factory extension for code-first development.
- UI is great for beginners and quick prototyping
- Code-based approach is better for CI/CD and team collaboration
- Use Azure DevOps for pipeline deployment automation
Learning Resources and Documentation
Microsoft provides extensive documentation and tutorials to help you master ADF.
- Official Azure Data Factory Documentation
- Azure Friday Videos on Data Factory
- Hands-on labs on Microsoft Learn
What is Azure Data Factory used for?
Azure Data Factory is used to create, schedule, and manage data integration workflows. It helps move and transform data from various sources to destinations for analytics, reporting, and machine learning.
Is Azure Data Factory ETL or ELT?
Azure Data Factory supports both ETL and ELT patterns. You can transform data before loading (ETL) using tools like Mapping Data Flows or load first and transform in the destination (ELT) using platforms like Azure Synapse or Databricks.
How much does Azure Data Factory cost?
Azure Data Factory uses a pay-per-use model. You’re charged based on pipeline runs, data movement, and data flow execution. There’s a free tier with limited monthly activity units, making it cost-effective for small workloads.
Can ADF connect to on-premises data sources?
Yes, using the Self-Hosted Integration Runtime, Azure Data Factory can securely connect to on-premises databases and file systems like SQL Server, Oracle, and local folders.
How does ADF compare to SSIS?
While SSIS is a traditional on-premises ETL tool, Azure Data Factory is cloud-native, serverless, and more scalable. ADF can also run SSIS packages in the cloud using the SSIS Integration Runtime, enabling hybrid scenarios.
Azure Data Factory is more than just a data integration tool—it’s a powerful orchestration engine that empowers organizations to automate, scale, and secure their data workflows in the cloud. From simple data movement to complex ELT pipelines, ADF provides the flexibility and reliability needed in modern data architectures. Whether you’re migrating legacy systems, building real-time analytics, or feeding AI models, mastering Azure Data Factory is a critical step toward data excellence.
Recommended for you 👇
Further Reading: